There’s a currently growing trend in website design where website owners request access to send you notifications. I can’t think of a case where this would ever be required or wanted and yet many websites are asking, sometimes even before the content has fully loaded.
To block all notification requests and all notifications from all websites in Firefox, type “about:config” in the address bar and search for “dom.webnotifications.enabled”. Double click that row to set the value to false and enjoy a happy, interruption-free web browse.
While you’re at it, read up on and consider enabling Tracking Protection for all websites. It makes browsing much faster as it skips the ads from shady advertising companies while you’re on your favourite sites.
I was very happy to receive this in my inbox the other day. Specifically, it relates to the suit brought against Geocoder.ca by Canada Post over crowd-sourced lists of Canadian Postal codes. Here’s a copy of the email, in its entirety.
—
Geocoder.ca
Lawsuit Update
This is the final update on the status of Canada Post’s copyright/trademark lawsuit against Geocoder.ca, Ervin Ruci and Geolytica.
Canada Post has discontinued this lawsuit.
The terms of settlement are confidential but our agreed statement is this:
Canada Post commenced court proceedings in 2012 against Geolytica Inc. for copyright infringement in relation to Geolytica Inc.’s Canadian Postal Code Geocoded Dataset and related services offered on its website at geocoder.ca. The parties have now settled their dispute and Canada Post will discontinue the court proceedings. The postal codes returned by various geocoder interface APIs and downloadable on geocoder.ca, are estimated via a crowdsourcing process. They are not licensed by geocoder.ca from Canada Post, the entity responsible for assigning postal codes to street addresses. Geolytica continues to offer its products and services, using the postal code data it has collected via a crowdsourcing process which it created.
While it is unfortunate that it took Canada Post 4 years to come to this conclusion, this turn of events reinforces our long held position that our postal code data is crowd sourced.
As this is the last (mass) email you will receive on this topic, we thank you for your support and wish you all an “open data” future.
P.S. All excess donations and/or other funds we have received at the conclusion of this lawsuit, will be donated to those who conducted our legal defense pro bono over the past four years of legal wrangling, with special thanks to the Canadian Internet Policy and Public Interest Clinic (CIPPIC) and RIDOUT & MAYBEE LLP.
—
I’m glad we can finally put that to rest. Good luck out there, geocoder.ca!
I think most Canadians would agree that it’s fair for Canada Post to charge companies for a list of Canadian postal codes by region, since it does require actual work to organize and maintain that list. What I think most Canadians would disagree on is suing someone for building their own list from scratch, based on people submitting their address and postal code to help out. But, that’s exactly what’s happened to Geocoder.ca, an Ottawa-based mapping firm which supplies the postal codes to free and open mapping services like OpenStreetMap.
This is the gist of the matter: Since 2004 we have crowdsourced* the generation of the “Canadian Postal Code Geocoded Database.” When you make a query to geocoder containing for example this information “1435 Prince of Wales, Ottawa, ON K2C 1N5”, we then extract the postal code “K2C 1N5” and insert it into the database that you may download for free on this website.
It’s been nearly 4 years since they’ve been sued and they’re finally going to see their day in court soon.
And that leads to me to the final thing I want to talk about, which is also the most important: Twitter has fucked up its platform. Twitter has turned into a place where famous people and news organizations broadcast text. That’s it. Nothing great is Built On Twitter, even though it should be the most powerful realtime communications platform on Earth. There are simply no developer integration features for building stuff on top of Twitter as a platform, and that is absurd and disappointing. The fact that automatic tweets from apps are considered rude is one of the biggest failings of Twitter’s product team–Twitter should be the place for apps to broadcast realtime information about someone. And yet the culture around the Twitter community has effectively banned such behavior because the product doesn’t have features to filter/organize such notifications.
Twitter started off as a content creator’s dream. They had a freely available API and a massive, growing data-set open to anyone with some basic programming skills. That avenue was closed a few years after launch when they bit the hand that fed them and blocked basic API access to successful apps.
While I agree with Mr. Curtis’ overall opinion of the Twitter platform, I’m not convinced Twitter is “the right person for the job.” The service that Twitter provides should be given to the people who contribute to it, like Wikipedia does. The content and the platform should be completely open. Giving this responsibility to one for-profit company is simply a ticking time bomb.
It’s for this reason that I recommend as many interested people as possible look into running or contributing to the GNU Social platform. It’s a federated Twitter-alike service that’s completely open-source. People on one network can follow and reply to people who are on another. Even better is that there’s no 140-character limit!
Finally got around to updating my version of Notepad++. Was surprised but then delighted by this nugget that types itself out when it restarts:
Freedom of expression is like the air we breathe, we don’t feel it, until people take it away from us.
For this reason, Je suis Charlie, not because I endorse everything they published, but because I cherish the right to speak out freely without risk even when it offends others.
And no, you cannot just take someone’s life for whatever he/she expressed.
Hence this “Je suis Charlie” edition.
– #JeSuisCharlie
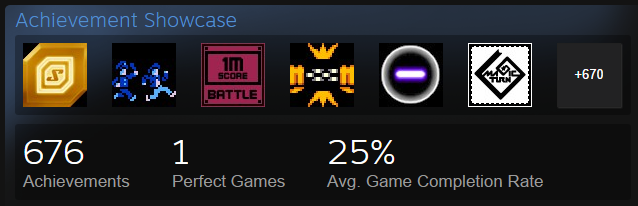
For the past few weeks I’ve been on a personal mission to go through each of the games in my Steam library, one by one, and complete all of the achievements in them. This is known on Steam as a “perfect game.” and is listed in your profile page as such. So far, I’ve got one perfect game, but many others are very close. This award is binary, giving the impression that I’ve only played one game out of my list. This means if I have 99/100 achievements, it will not give me a “perfect game.” I have hundreds of games to play so it’s unlikely I’ll ever actually finish this. Still, it’s something fun to do.
If you’re not familiar with the concept of Achievements, think of Scouts badges: you get badges for completing certain actions in a game up and above the basic gameplay. An example might be completing the entire game without dying or finding all of the hidden gems in a level. They don’t directly affect gameplay but provide an interesting meta-game which encourages players to come back (known as replayability) and also gives a sense of completion when you’ve achieved them all.
There is also a listing, on Steam, which shows, per game, what percentage of players have gotten each achievement. For example, here is the achievement listing for a game called Race The Sun, which is a bit like a racing game where you also have to dodge obstacles.
All this is well and good, but who decides what these achievements will be? The game developers themselves. This is where we get into a sort of gray area where, if the achievements are garbage, they actually serve to disicentivize continuing to play the game. Below, I’ll provide a few examples of these “Anti-chievements.”
1. The “Play for X Number of Hours” Anti-chievement
Hey! You’ve already completed the game but to get this last achievement, you have to rack up some insane amount of hours just to say you did. Let’s say 50 hours? Excellent! This is fun!
You’ll note that only 1.2% of players have gotten this anti-chievement. I wonder why!
2. The “Do a Mundane, Repetitive Task X Times” Anti-chievement
There is a game in my Steam library that gives you an achievement once you click your mouse 500,000 times. Let that sink in for a minute.
Clickr: Click 500,000 times.
3. The “Order of Magnitude Score” Anti-chievement
This one sometimes appears alongside #2 but instead of jumping right to 500,000 clicks, you get achievements at 1000, 10000, 100000, then 500000 clicks. Count ’em: that’s FOUR achievements you get. Just for clicking! Aren’t you happy?
4. The “Play it all again” Anti-chievement
Wizorb is the most notable for this transgression. Part of the game has you rebuild a village over time using the coins you collect during game play. But, after you’ve beaten a large portion of the game, you may realize that there is an achievement for beating the game without rebuilding the town. If you didn’t notice this before you started playing, you would have gotten hours and hours into it, only to have to restart and replay the game again without doing this one thing at the very beginning.
5. The “Rely Completely On Luck” Anti-chievement
Faerie Solitaire was a fantastic game. The achievements were pretty good, overall, and would appear naturally as you progressed through the game. Still, there were two that most people never got and it’s not because they were bad at the game. They never got them because receiving the achievements were based entirely on random luck.
Essentially, during game play, there is a small chance that an item will drop. That item gives you the two achievements. The only way to get this item is to keep playing the game, even after you’ve long gotten every other achievement and beaten it many times in the hope that maybe you’ll win the lottery.
6. (Bonus) The Multiplayer Anti-chievement
If you are an indie game developer, please do not make multiplayer achievements for your game until you’ve got a large and thriving online multiplayer community in your game. Many games, even from small developers, will include some sort of “play against other people online” component. The trouble is that indie games tend to not have enough people on during the day for players to actually compete. So, in this case, it’s impossible to get achievements based around the multiplayer component of the game.
I recently got some harsh and direct feedback from a person that I trust.
It was hard to listen to, but I needed to hear it.
For the past two years, I have lived alone. I’m responsible for me in almost every respect. In those two years, my skin has grown thicker, my balls bigger, and my confidence stronger. Because of this, it feels like going against the grain in society has become normal.
Many times over the course of a day someone whom I don’t know will point and laugh at me on my ebike or will criticize my decisions as former group lead of GDG Waterloo. Sometimes it’s hard to live with, but in a way I’ve just gotten used to shrugging it off and doing it my way because, well, everyone’s a critic.
We live in a very judgemental society. Everyone is looking with disdain at someone else who may be different in some respect. Because of this noise, it’s too easy to miss or dismiss signal.
As much as I wanted to say that the reason I failed was because of someone else or something else, that’s just not the case. He called me on it and made me face it, and I’m stronger for it. You can bet that I’ll be doing my best to make sure it doesn’t happen again.
I’ve read this and re-read it trying to think about exactly what it is I’m trying to say. I think it is: We can’t see ourselves as others see us, no matter how hard we try or how much we think we can. When someone criticizes you and they’re right, admit it. To them and to you. Face the truth, no matter how hard it is, and do the right things to fix it.
Last month, I bought an e-bike. It’s an Emmo Alien. I got it used on Kijiji for $600. Where I live, it doesn’t require insurance or a license to ride. It costs me nothing to charge since my rent includes utilities.
Emmo Alien E-bike. Mine’s black, though.
Like pretty much everyone in Canada, I’ve had at least one bike at any point in my life. I never once considered riding it to work. My mental picture of a person that biked to work was a sun-glassed, angry man in really tight spandex. I couldn’t imagine biking all the way to work, sweating the whole way there, angry at other drivers for cutting them off or not knowing the rules. It’s just not for me. It felt like riding a bike to work meant you had to join some sort of environmental cult.
The truth is, while I care very much about the environment, I’m a cheapskate. And I’m lazy. Riding an e-bike is free. And I don’t just mean free as in beer. It feels free, as in freedom. I haven’t used my car in so long, a tire went flat from sitting. The insurance on my car (never mind gas or repairs) per year pays for more than two e-bikes per year. I could actually buy a second one, put it into a dumpster, light it on fire, and I would still be ahead.
And, do you know what? Riding an e-bike is fun! It’s liberating. My girlfriend finds it empowering. She’s never gotten the hang of riding a regular bike, but she’s learned how to ride the e-bike. We do groceries (it has hooks to put the bags as well as two storage compartments), we go for picnics, we go out and get fresh air, we get some sun.
Sure, a cyclist looks ridiculous, but when a driver in a big pickup truck zooms past in a testosterone-filled money-burning pissing contest, who looks more ridiculous?
I’m a bit late in posting this, but June is Bike Month in Waterloo Region. The thing is, it doesn’t have to be just June or just Waterloo Region. Have you ever tried biking to work? Do it tomorrow and let me know what you think.
If you’re interested in some data, it takes about 7 hours to charge from completely empty to completely full. A full charge lasts me about 2 and a half hours of continuous use, or about 50-70km, depending on whether or not it’s just me or with a passenger. My trip to work (including to McDonalds for breakfast) is 7.5km, each way. I do this trip Monday to Friday, rain or shine.
The single largest trip I’ve made on the ebike so far. With a passenger. Had half charge left when I got home.
The one reason I don’t is because of the bullshit link-up between it and YouTube, where they try to change your channel name to match your Google+ profile. I love my YouTube and don’t want things fucking with it, thanks.
Seriously? Like, nobody at Dropbox stopped for a second and thought: “hmm, are we sure we’re sending the right message, what with the still-in-the-news revelations of the illegal USA surveillance and all?”
People who know me know I love Dropbox. I blogged about it here back in 2009. I’ve been a paying member for years. I’ve got two accounts. Well, had. I’ve cancelled them both and switched to BitTorrent Sync since this news broke.
Here’s a blog post you wouldn’t normally expect to see on this blog. In the past, I’ve not usually been big on the Microsoft stuff. That is quickly turning around. Take a look at all the amazing stuff they did in the last day:
I’ve had my Oculus Rift Developer Kit Version 1 (DK1) for just under a year, after receiving my kit on April 11, 2013. In that year, I’ve built a few apps and played with a ton of other people’s apps from Oculus Share. My experience with the DK1 is that, while it’s good, it’s not great. It’s funny, because, while the low resolution and heavy screen-door effect were the two initial problems I had with the unit, over time, they took a back seat to another, more basic problem:
The Oculus Rift DK1 wire is fucking annoying. Not just annoying, but a lot of the time it ruins the experience of immersing yourself in the virtual environment. The new term that people are using for this is “presence.” When I’m wearing it, I can’t turn around fully without feeling the wire tickle my neck or hear the breakout box slide across my desk, which makes me worry that it’ll fall off and I’ll break it, so I take the headset off to make sure it’s safe. The wire undoes exactly what the rest of the kit is trying so hard (and succeeding, mostly) to do: immerse me in the experience. All the time that I use the unit, I fear of fully moving in any direction because the wire is there.
That wire has got to go.
I know that Oculus is working its hardest to reduce the latency between the time that you move and the time it shows the movement on the screen in the headset. I know that going wireless will increase that latency. But, hot damn, at this point, I’m almost willing to take a slightly more delayed response if I can do without the wire.
My first reaction, similar to that of most other developers who are working with the Oculus Rift, upon hearing of the Facebook acquisition of Oculus, was one of intense disappointment. It felt like our favourite band just sold out to a huge record label. Oculus was the embodiment of the VR industry itself: the scrappy little guy, fighting against all odds to prove to the world that he can do it.
All that changed this past week when it was announced that Facebook acquired Oculus.
Enough has been typed and said over the past week, with emotions ranging from “take our ball and go home” to “this is the best thing that could have happened to us.” After letting it settle, thinking about it, seeing John Carmack give his support, then Michael Abrash leaving Valve to join the team, my feelings on it have completely changed. This change at Oculus is a big deal, in a good way. Oculus now has the best chance of making true VR a reality. They have the best team in the world and the biggest budget behind them to do it. Colour me excited.
Counter Strike Global Offensive (CS:GO), a game I have been playing often since summer of last year (2013), is currently facing a dilemma that all online multiplayer games (and many social networks) face: as it grows in popularity, which is required to grow the monetary kick-back for developing and running the service as well as pushing the service’s features forward, the average level of player maturity decreases in proportion, to the point where older players who are used to playing with a more mature player-base will flee the game for some other outlet until this process takes over that one, and so on. It’s important to note that I’m not speaking about the skill of CS:GO players, since that is handled quite well by their Elo ranking system, but instead the maturity level, which means things like the level of racist voice and text chat, lack of statesmanship, etc.
Is there a way to programmatically ensure that higher-maturity players do not intersect with lower-maturity players while not specifically removing the lower-maturity players from the player-base, since those lower-maturity players are required to keep the service growing?
My idea is that the service would have two or more pools of players, which would be kept secret from the player-base. My supposition is that lower-maturity players are “high-churn” in that they will likely not stick with the game for a great length of time and will instead switch their attention to some new game that arrives 3-6 months later. This “high-churn” player-base would essentially subsidize the higher-maturity players and game without the higher-maturity players ever having to intersect in game-play with them.
How do you detect an asshole, in code?
My guess is that this will have to be done in a similar way to detecting email spaminess: users will have a value between 1 and 100 for assholery. Being an asshole in online forums such as games is not binary (being either true or false) nor can any one action or decider change your state to true or false. So, it will have to be a collection of actions, over a given space of time, which will increase or decrease your assholery value.
Counter Strike Global Offensive offers a way for players to report users for griefing which offers one opportunity, though I’m not sure how much weight to put on it since it could be easily gamed directly by the assholes we’re trying to prevent.
A manual process is, at first glance, out of the question, since it’s not scalable. Thousands of games are on at any given point in a day. How could you possibly oversee them to identify assholes? Here, Counter Strike Global Offensive offers us a unique idea: Overwatch. As a developer, this solution smells bad because it feels like something we should be able to automate.
Perhaps a combination of encouraging users to not act this way combined with an Overwatch-for-Assholes system would reduce it.
I don’t have an answer
This problem is not going away and will only get worse as the gaming population grows.
With all the recent news about the US government collecting and analyzing everything we do online and in our daily lives, we’ve all been looking for ways to increase our privacy.
Today, an article was posted on Hacker News about Google Analytics not being served over https. After reading this, I remembered that I use it and questioned whether or not I should keep it on this blog. Google Analytics has been installed on this blog for years, but today I found it hard to answer exactly why. It provides no real value to me other than satisfying my curiosity.
In the end, I decided to remove it. Not only because it is not served over https, but because the only real parties it benefits are Google and the NSA. My site is not large or popular, but it’s just one less site on the network being tracked through that channel.
I believe, in life, we should lead by example. I believe the web should be secure by default. I believe web servers should only function when using encryption (Supporting http was a design flaw, https should have been the only option. Even a self-signed certificate is safer than plaintext http.)
To that end, I’ve come up with a short list of simple things us website owners can do in order to hinder attacks or snooping by third parties. I’ll compare my own site against this post and update as I move toward compliance (red means failure):
Serve content only when encrypted by perfect forward secrecy.
Serve content entirely from web hosts and CDNs under your control.
Encourage others to do the same.
It’s amazing how quickly my view on this has changed. If you would have asked me a year ago whether or not it was important to self-host images and scripts used on your site (or whether you should even be hosting your blog yourself versus using a third-party service like Tumblr), I would have answered an emphatic no and provided many reasons why letting a bigger, better player handle that is much better. As a site operator, I want my site to be as fast as possible. As a web user, I want to be as secure as possible. Which is more important?
With the way things are now, it’s worth being a second or two slower to serve knowing that your stuff is your own.
It’s an issue that’s dear to my heart, especially since I spent 5 years in walkable, lovely downtown Guelph. After getting the gig with Ivan, I knew that I’d have to move here, so I found a spot to rent across the street from Communitech on Victoria (I’m right across from Oak St., near the green Vidyard home).
I use my car to go a few blocks, just as you said, and I hate it. I would never have done such a thing in Guelph. After living here for 10 months, there are certain things that make being a pedestrian almost impossible.
We need a pedestrian-first mindset in this city. Here’s what I think needs to change to support that:
40km/h speed limit in the Innovation District, rather than the 50km/h default, strictly enforced
All intersections default to crosswalks on. Currently, if you don’t press the crosswalk button on the corner of Victoria and Joseph (Communitech’s location), you are not allowed to walk across the street even when the light turns green (and lasts < 10 seconds I might add)
Pedestrian crossing light on Joseph for people who park in the stone parking lots behind Communitech. Currently, everyone j-walks and it’s very dangerous, especially in bad weather
A “scramble” crosswalk at the corner of Charles and Francis, giving us tech workers quick and easy access to food downtown without fear of being run over (I see many people crossing diagonally already)
To help support the discussion on this topic and keep the ball rolling, I’m going to CC this email to my blog. Is there a forum I can link to, as well, in case people have responses?
When showing someone your start-up/product/service, it’s easy to let them guide your thinking unconsciously. It feels like there’s an inverse proportion of weight given to feedback to sample size, especially if it’s the first time taking the cover off.
Here’s a really great example of why one should always take every bit of advice as advice and not gospel: